
Empowering NDIS Participants with Multi-Agent Retrieval AI
Introduction
The National Disability Insurance Scheme (NDIS) relies on a large body of policy documents, guidelines, and operational rules. These documents are published across hundreds of PDFs and are updated frequently. Participants must understand this information to make informed decisions about funding, eligibility, and support.
Accessing clear and reliable information is critical, but the volume and complexity of material creates barriers for many participants.
The Problem
Participants are expected to understand and act on complex policy information distributed across many documents. Finding a clear answer often requires reading multiple PDFs, cross-referencing sections, and checking whether information is current.
As a result, participants frequently depend on informal advice, support coordinators, or paid experts to interpret policy on their behalf. This reliance can lead to inconsistent guidance, outdated interpretations, and reduced confidence.
General-purpose AI chatbots, including those based on large language models, are not well-suited to this problem. They cannot guarantee that answers reflect the most current policy versions or provide verifiable links to authoritative sources. In a regulated system like the NDIS, this lack of traceability creates risk and limits trust.
Requirements and Constraints
- Responses must be based only on official NDIS documents and reflect the most recent policy updates.
- The system must provide transparent source references for participants and support staff to verify information.
These requirements rule out standalone LLMs or simple chatbots that generate answers without strict document grounding.
The Solution
A retrieval-based AI system was developed. It combines a controlled document retrieval process with LLM reasoning. Instead of relying on general training data, the system retrieves relevant sections from official NDIS documents and uses them as the sole source for generating responses.
System Design Overview
The system operates through a controlled ingestion and query workflow designed to ensure accuracy, traceability, and up-to-date information.
Official NDIS documents are uploaded via an admin panel and stored in an Amazon S3 bucket. The documents are then processed into vector embeddings stored in a PostgreSQL database with metadata such as document identifiers, section references, and page numbers.
High-Level Architecture
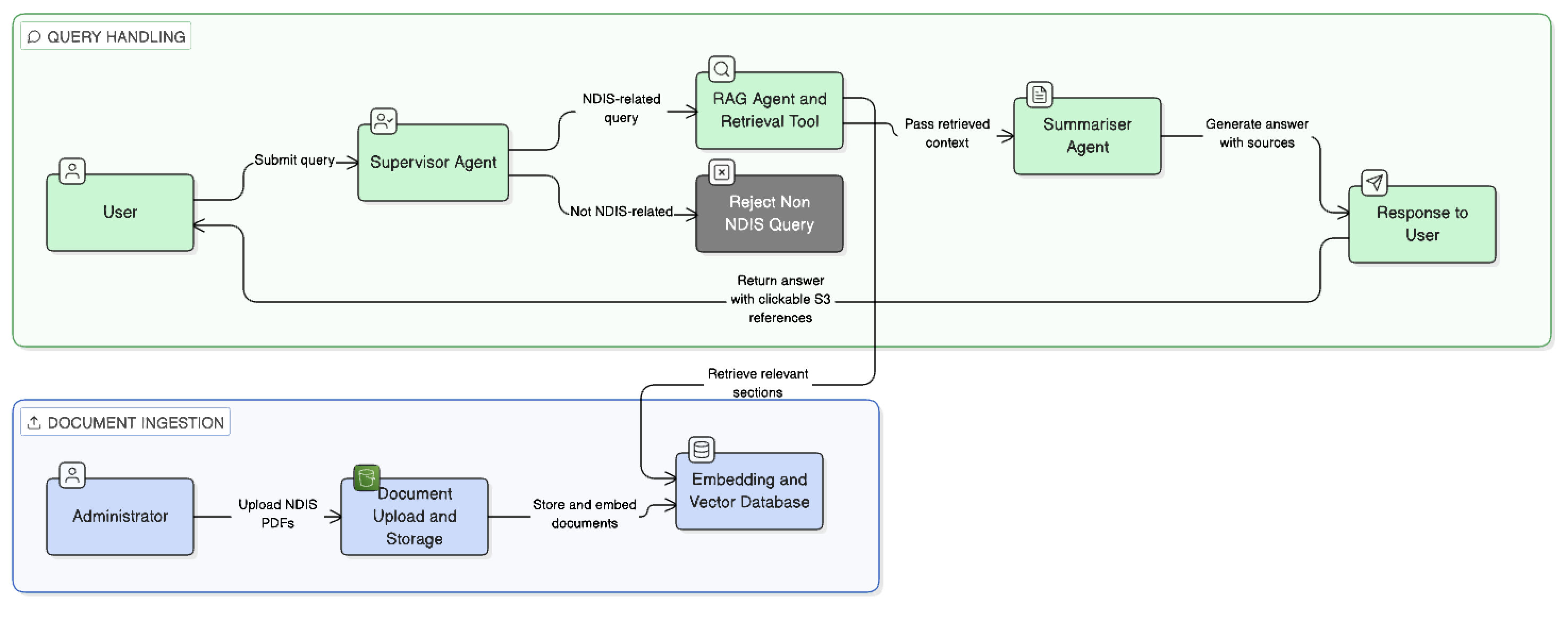
This ingestion process allows new or updated NDIS documents to be added without retraining the language model.
When a user submits a query:
- A supervisor agent checks if the query relates to NDIS-specific policy.
- Queries outside the scope are returned with a fallback response.
- NDIS-related queries are routed to a RAG agent.
- The RAG agent retrieves relevant document sections via vector similarity search in the pgvector database.
- A summariser agent generates a concise response from the retrieved content.
- Responses include structured source references linking back to the S3 documents.
Multi-Agent Graph Example
createGraph(onToken: (token: string) => void) {
const graph = new StateGraph(this.agenticState)
.addNode(supervisorAgentName, async (state) => await this.supervisorAgent.call(state, onToken))
.addNode(userAgentName, async (state) => await this.userAgent.call(state, onToken))
.addNode(ragAgentName, async (state) => await this.ragAgent.call(state, onToken))
.addNode(summarizerAgentName, async (state) => await this.summarizerAgent.call(state, onToken))
.addEdge(START, supervisorAgentName)
.addConditionalEdges(supervisorAgentName, (state) => state.nextNode)
.addEdge(userAgentName, summarizerAgentName)
.addEdge(ragAgentName, summarizerAgentName)
.addEdge(summarizerAgentName, END)
.compile();
return graph;
}
Response Example:
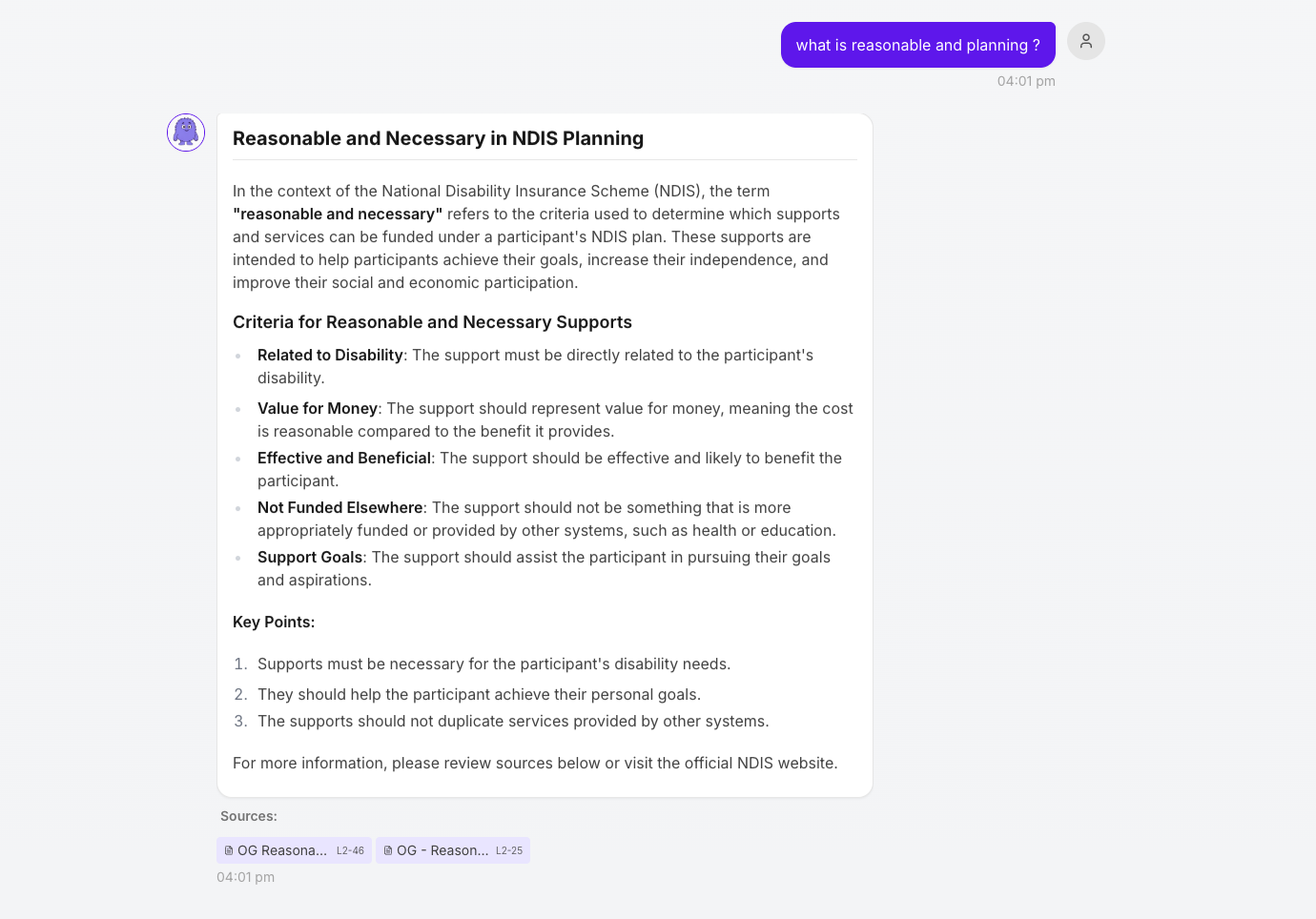
Cited Document Opened:

Outcomes and Impact
The retrieval-based system improved access to policy information by providing accurate, document-grounded answers in plain language. The presence of clear source references reduced reliance on third-party interpretation and supported informed decision-making.
Moreover, hundreds of NDIS documents can now be queried efficiently, making it easier to provide timely, up-to date guidance to participants.
Lessons Learned
Retrieval quality is critical. Embedding model choice and chunking strategy affect accuracy, especially for nuanced policy language.
Without AI evals, incorrect answers can appear correct. Real user feedback helps identify gaps.
Conclusion
LLMs are powerful but insufficient alone for regulated and large information environments like the NDIS. By combining LLM reasoning with a retrieval-based pipeline, guardrails, and transparent sourcing, the system delivers accurate, verifiable, and participant-focused information.
Want to discuss how we can help your business?
Book a Free Discovery Call
30 minSchedule an intro call with one of our lead software engineers